JILT 2000 (1) - Daniel Austin et al
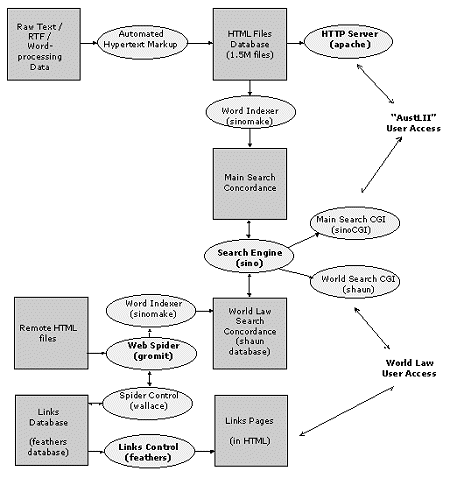
Figure 1 - AustLII Technical Overview From the user perspective, one of the most obvious features that distinguishes AustLII from other large text databases is the extent of the hypertext markup (currently with over 22 million links). AustLII employs no editorial staff to assist with hypertext markup. All hypertext links on AustLII's databases are inserted on an automated basis with no editorial input. The hypertext markup is achieved via a number of programs and scripts that employ similar approaches. Some of these are implemented in C and others are written in Perl. The general nature of the markup scripts is highly heuristic and is designed to identify a number of salient text features. Some of the things that are currently processed include:
Although some of these can be dealt with without reference to any contextual matters, a lot of these items are highly context sensitive. For the most part, all markup is done ahead of time. Dynamic markup is kept to an absolute minimum in order to maximise system performance. The major exception to this is in relation to the Noteup functions which are included for all legislative documents and some cases. The noteup function allows users to conduct canned sino searches which are based upon stored URL addresses. The effect of noteups is to perform a 'reverse hypertext lookup' - thereby returning related documents which refer to the current document. The main aims of the overall hypertext markup approach are that:
Unfortunately, these aims tend to be contradictory. Rich hypertext markup involves complexity and so challenges maintainability and speed of execution. Similarly, the more ambitious that the markup programs become in terms of identifying unusual text patterns, the greater the risk of error and so forth. The current markup approaches represent a set of design compromises that seek a balance between the constraints. This has been achieved over a number of years through experience with legal data. As further discussed below in the section on document management, the markup tools rely heavily on the use of file organisation for document management. Currently, there are no separate document control databases. Partly because of this and partly for reasons of markup efficiency, all hypertext links on the system can be mapped on a 'one way' basis. The central idea is that whenever a potential link is found, it is possible to determine an appropriate destination without any database lookups (other than a check to make sure that the target HTML file actually exists). 2.3.2 Contextual Sparse Natural Language Parsing In previous work on the DataLex Project, a fairly simplistic approach was initially adopted to identify hypertext links that relied upon simple pattern matching. Whilst this is quite acceptable for identifying obvious textual features (such as references to Act names), it is very restrictive otherwise. The approach adopted by most of the current markup programs is one of contextual sparse natural language parsing . This is a methodology that takes into account the context of where a potential hypertext link appears (including information that can be gleaned from previous and subsequent hypertext) as well as being capable of doing sophisticated parsing of disjointed pieces of textual material within a document. Context is very important for a lot of the markup and operates at various different levels. The scripts take into account simple things (such as, what type of document is being processed and the relevant jurisdiction), but often also need to take into account where words occur within a document and what has come before and what comes afterwards. The approach of sparse natural language parsing is similarly important. Unlike pattern matching (via regular expressions for example), parsers have the potential to operate more subtly and also to take account of the context under which they are operating. The hypertext markup programs and scripts vary dramatically in their level of sophistication, but mostly work along similar lines. Some of these are of general application and others are more specialised. One of the most commonly used and most easily explained programs is called findacts . This is a program that recognises references to Act and Regulation names, to references to Parts and Divisions of legislation and to section references. An interface to findacts is provided on the main page of AustLII to assist organisations that wish to add their own links to AustLII legislation. Findacts works by first finding apparent references to legislation. Often these are simple to find (by the occurrence of the word 'Act' for example), but on other occasions these are more difficult (for example, a reference to 'the Constitution' or to the 'Corporations Law'). Once found the sparse parser operates to gather in the complete name of the piece of legislation and does a check to determine the appropriate jurisdiction (possibly with 'hints' from the calling program). It then checks to see that AustLII holds an Act or a Regulation by that name (after completing the name, by the addition of a year or converting an abbreviated form as necessary). If successful, a hypertext link is inserted for the reference found. The program then examines the surrounding text and, in the context of the Act or Regulation found, tries to determine if there are any internal references to it. This is done via a process of repetitive sparse parsing and where a reference or series or references are identified, these too are marked up. Findacts also is a tool that is used to markup individual pieces of legislation. In this case, context is much more important. The program takes account of the Act that is being marked up and changes its assumptions (as the majority of references are likely to be internal). For example, it takes account of likely references to pieces of related legislation (for example, where the text in a Regulation appears to be referring to a section, the software is intelligent enough to assume that this is to the enacting Act). The most complex markup that AustLII currently does is in relation to legislation. In one sense, legislation is an easy target for automated hypertext markup: it has hierarchy, order and, to some extent, consistency. The difficulty is that all of these advantages are embodied in natural language, which needs to be identified and responded to. The current approach to legislative markup is to deal with the underlying text as a set of problems in series. In some ways the most vital step is to just gather in the basic organisational information (such as simple things like where sections start and stop). This type of information is often difficult to reliably generate from what is often just effectively ASCII text. Nevertheless, it is vital both in practical terms of dividing an Act up into its component parts for delivery purposes as well as the more difficult issue of understanding the context of words that appear within it. Once the basic elements of a piece of legislation have been determined, the next step is to pass the text through the findacts program which is passed the context that it is marking up an Act, the Act name, any related pieces of legislation and so forth. Findacts also internally takes account of where in an Act it is and makes adjustments as necessary. Other programs follow to reprocess the data adding links as they go. One of the more important of these is a program called finddefs . The task of finddefs is to identify and mark up references to internal definitional terms within an Act or Regulation. Definitions in legislation can be global, at Part level, or just refer to particular Divisions or even sections. Finddefs deals with these contextual issues and inserts links as appropriate. The rest of the legislative markup ends with a call to a tool called act2html which does the final division of the legislation into individual HTML files, tidies up the Table of Contents (or builds a new one if none is present), adds legislative Notes and many other things. Another example of a tool that performs automated markup is a program called findcases . With the advent of vendor neutral and medium neutral citation[ 15 ], referring to case law and automatically inserting links to it has become much easier. In respect of the historical material however, there still exists a difficult technical challenge. Conventional case citation refers to cases on the basis of where they are published. A case can appear in multiple series of reports from different publishers and although for most courts there is a preferred (or 'authorised') series of reports, there is no guarantee that this citation will be present. The role of findcases is threefold: it extracts parallel citation references from cases in the database and matches these to file names; it identifies references in text to things that appear to be citations and that appear in the citation/filename list; and it does the actual replacements of citations with hypertext links. Apart from the hypertext markup software, the centrepiece of the current AustLII system software is the sino search engine. Sino is designed for simplicity and speed. The software is written in C and is very compact[ 16 ]. The major trade-off in sino's design was to sacrifice disk usage for speed of execution[ 17 ].
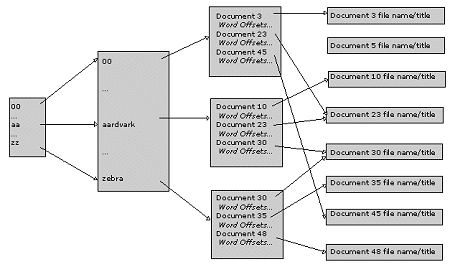
Figure 2: The Sino Concordance 2.4.1 The Sino Concordance Structure Like most search engines, sino relies upon a word occurrence database (sometimes called a concordance or an inverted file ) to speed up search times. This database consists of a dictionary of every word in the indexed text files, along with linked references to the documents and word offsets for each occurrence of each word. The sino concordance consists of several files. The word dictionary is stored in a file called .sino_words and consists of a sparse index based upon the first two characters of its contents, followed by a compressed list of the words themselves and an offset to the location of occurrence information. The word occurrence information is stored in a file called .sino_hits . This file contains one block of information for each word. This starts with a header setting out the number of entries that exist for the word and the number of times that the word occurs. The occurrences (or hits ) are stored as a series of 32-bit references to a document number followed by word offsets within each document. The document number is a reference to a third file called .sino_docs which gives information about individual documents. This is an ASCII file, which maps document numbers to the name of the file that has been indexed, the HTML title of the document (to save individual file lookups when presenting search results), the date of the document and the size of the document. The concordance ratio (that is the size of the text indexed versus the size of the index files) is around 40%. Although this is relatively large, the concordance is easy to read and minimises unnecessary file input/output. Although concordance building on the current model is very memory intensive (using up to 300M of core memory), the build times are very fast. In sustained terms, the sino database creation utility ( sinomake ) is processing about 500M of text per hour. In execution, the sino search interface uses very little memory. For Boolean searches, the amount of memory that is used per search is around 250K. For freeform ('conceptual' - now known as 'any of these words') searches, this figure increases to about 400K. The sizes of the temporary files that it generates are fairly large (up to 200M for complex searches). From an interface perspective, sino offers a flexible set of alternative mechanisms. At the simplest level, it can be invoked in a non-interactive fashion to perform a single search and to return results. It also has an 'interactive' interface that is suitable for processing by custom written scripts that make use of pipes or Unix sockets. For this purpose, sino supports a simple command language. A typical interactive sino session follows:
Figure 3: Low level communication with sino This approach is very flexible and means that sino searches can be easily shared across a number of machines. Sino also supports a full C language API and has an associated C library. From a user perspective, the sino user search parser is very forgiving. It will accept searches in a number of standard search languages which legal researchers might be familiar with. The current search syntaxes which are recognised include Lexis, Status, Info-One (now Butterworths On-line), DiskROM (now LBC), C and agrep. The desire to handle all of these command languages mean that there have been a number of tradeoffs (eg the use of characters such as minus for a Boolean 'not' in Status). Nevertheless, the compromise is designed to work in the majority of cases and seems generally to work well. 2.4.3 Freeform Searching and Ranking Issues Apart from conventional Boolean searches, sino also supports 'freeform' (that is, 'conceptual') searches. These sorts of searches do not involve the need for operators or other formal syntax and are designed for users who do not have experience with Boolean systems. Freeform searches are processed as follows:
The current formula that is used to determine the relative weighting of each word occurrence (or 'hit') is:
Figure 4: The Sino Freeform Ranking Algorithm The effect of this ranking algorithm is to yield a percentage. A document receives 100% where it contains all of the search terms and the greatest number of ranked hits. The relative 'importance' of other documents is proportional to this figure. As is the case with most conceptual ranking systems of this type, the correctness of the search results is best judged in terms of their usefulness from a user perspective. Whilst it is a bit difficult to gauge this with total accuracy, it appears from user feedback that the approach seems to work well. The ranking mechanism for Boolean search results works on a similar basis. Apart from the databases which are stored on the system proper, AustLII also provides a database of links to other Australian and international legal web sites. Originally this index was searchable only by searching link titles and keyword descriptions. However the index (called Feathers ) has since been combined with AustLII's web spider, and now the full text of most indexed sites can also be searched. 2.5.1 The Feathers Indexing Software Originally, the links database was maintained manually, but it grew rapidly and contained more than 500 entries by the middle of 1996. In order to maintain this list on a more sustainable basis, Geoffrey King wrote a database management system (initially called Chain, but later renamed Feathers ) which was based around an SQL back end. This software provided a new user interface that allowed hierarchical browsing and used sino to provide text search facilities. It also introduced an easy to use interface for editing and maintenance of index entries. The Feathers database has been redeveloped by Austin and has grown to about 4,000[ 18 ] references to external web pages. From a user perspective, these can be browsed on the basis of their source (categorised by countries and jurisdictions) or by subject . There are 50 'top-level' categories and these are organised and divided in a way that is similar to the conventional paper based Australian legal subject indexes. The database is maintained manually by AustLII secondary materials staff. Users may also contribute links, but these are edited and approved by AustLII editorial staff prior to being added to the database. 2.5.2 The Gromit Targeted Web Spider There are a large number of generalised search engines that facilitate searching of web pages (Alta Vista, Lycos and the like). From a legal research perspective, there are two problems with these sorts of system: they generally do not index pages exhaustively and the quantity of data makes legally specific searches difficult. A recent paper estimated that general search engines do not index more than 16% of the web and can take several months to find new pages or update their databases[ 19 ]. In 1997, Austin wrote the first version of a targeted web spider that was designed to overcome these difficulties. The program is called gromit and has an associated interface and control program called wallace . The aim of the system is to index web pages and make them searchable via sino , but to be selective about what sites are indexed and to be exhaustive in respect of relevant legal material. In the current system, gromit makes use of the feathers database to select which sites it indexes. As a major information repository, and in response to the impact of other web spiders on the AustLII system, gromit is very conservative about the loads that it places on the remotely hosted sites that it is indexing. Apart from the generally accepted compliance to the Robots Exclusion Protocol, it also ensures that no site is accessed twice in a 1-minute period. Where implemented, gromit also takes advantage of appropriate HTTP headers (such as If-Modified-Since and Last-Modified ). AustLII has recently received a major grant from the Asian Development Bank ( Project DIAL ) to remotely index the legislation and laws of 11 developing Asian countries. The prototype of this facility in many respects provided the impetus for the creation of gromit . As more information providers publish their own material, the significance of distributed indexing will become very important for the project. 2.6 The Wysh Distributed Inferencing Engine As part of the work on an ARC funded research project and following on from the earlier research conducted as part of the DataLex Project , AustLII is conducting research and development into the production of scalable enhancements to the service based around artificial intelligence technologies and in particular expert systems. The essence of this aspect of AustLII's research is to investigate how inferencing technologies can be used to 'add value' to underlying legislative data on a massive scale over the Internet. 2.6.1 The Ysh Expert Systems Shell The current approach is to use an expert systems shell called ysh that had been previously developed. Ysh is a quasi-natural language based expert systems shell that supports simple propositional logic. The system is primarily rule based and by default all rules are both backward and forward chaining. The quasi-natural language based knowledge representation allows for rules to be written in a close paraphrase of the underlying legislation that is being modelled. All dialogues, explanations and reports which are generated by the system are constructed dynamically by parsing and manipulating the English sentences which are used in rules. Ysh also has limited support for case-based reasoning (based around Alan Tyree's pannda system) and general document generation. The wysh interface was written by King and Cant to facilitate the operation of ysh consultations over the Web. This operates using an inferencing server which maintains state information that is associated with each user session on the server (over separate Unix sockets) and uses a simple forms based approach at the client end. Wysh reads knowledgebases directly from HTML pages. An important feature of wysh is that knowledgebases can be distributed across different machines and pages. The wysh interface is tightly coupled with the underlying hypertext paradigm and makes use of sino to provide search facilities. Hypertext links can be added in all consultations and reports either explicitly or automatically (using tools such as findacts ). The knowledgbases themselves form part of the system and can be displayed or searched over in standard fashion. 3. Current Feedback from Users From a technical perspective, the AustLII system is a diverse one and is constantly being changed to keep up with the growing size of the database and add increased functionality. This section discusses a few of the current issues and indicates current and likely future systems development. In September 1998[ 20 ], AustLII ran its first user survey, designed to gather feedback on AustLII's user base and user attitudes towards AustLII's performance as a legal web site. The general tone of user's responses was quite positive, with 96% of respondants rating AustLII as being as good or better than other legal web sites, and 42% feeling that AustLII was the best legal web site they used. There were however a number of concerns reflected in user comments. Regular users may be familiar with some of the issues identified in the survey. Among the most common themes in the user's comments were:
These user problems stem in part from various technical problems, many of which are related to scalability. The main issues are identified below. Whilst AustLII's Sun Ultra computers are 64-bit capable, Solaris 2.6 is a 32-bit operating system. It's file system only uses 31 of those bits in its file pointers. This means that the largest file that can be stored on a Solaris 2.6 computer is 2 gigabytes[ 21 ]. In June of 1999 the AustLII search concordance exceeded this limit for the first time[ 22 ]. AustLII builds a search concordance over the entire set of AustLII databases (primary and secondary materials). The process typically takes eight hours. In this case the process could not complete, because the resulting concordance file was too big. In addition, it has become difficult to complete the World Law search concordance because the size of the dictionary (which must be kept in core memory) is prohibitively large. For performance reasons, the temptation to split the concordance has been resisted. A temporary solution has been to expand the list of common words (which aren't indexed) however this is unacceptable for a number of reasons, including loss of accuracy in search results. The single concordance approach also means that there can be unacceptable lead times between the time that a document is added to AustLII, and the time that it can start appearing in search results. Currently, work is focusing on a new concept in sino - that of a 'virtual concordance.' This is part of the new 'beta interface' and the embryonic Anarchivist , which is discussed below. The idea of a virtual concordance is to have multiple physical concordances linked and accessed as if they were a single concordance. Future investigations and research will be conducted into the viability of using HTTP to distribute components of a virtual concordance over multiple machines. Although this is not an entirely new idea this does represent a natural extension of the distributed web paradigm which, with increasing bandwidth, may become a practical proposition in performance terms. AustLII's approach to document management has been affected by the need to produce results under time constraints and competing considerations. When a new database is to be added AustLII starts by receiving sample documents from the data provider. Generally, AustLII requests documents be provided in RTF format, however this is not always possible. If the data provider supplies another format, then it is usually converted to RTF first before being converted into HTML. For acts, an intermediate standard format called STATUS is used. Standard HTML headers and footers are then added and the resulting document run through AustLII's automatic markup software. As part of the negotiation process with the data provider provisions are made for continuing data feeds. This is increasingly set up as an e-mail process, where the data provider is able to e-mail new documents which are automatically received and processed (thus, High Court judgements can be available on AustLII within minutes of being sent from the court). AustLII has also begun using Gromit to fetch updated data from remote sites before converting them on AustLII. The Commonwealth, ACT and South Australian legislation databases are maintained this way, using SCALEplus [ 23 ] as the data source. The recent addition of Tasmanian legislation[ 24 ] is also due to this process. Once established the markup and updating process becomes largely automatic. However the increasing number of databases and variety data sources and delivery mechanisms is becoming problematic in document management terms. In particular, the current approach means that each of the 86 databases currently published has its own unique 'front-end' scripts, which are controlled and understood only by their author. A further problem results from manual editing of databases. This happens rarely and is generally avoided, but is sometimes required to quickly remove a case from publication where a suppression order has been made or to correct significant markup problems. Currently no mechanisms exist for tracking this kind of work and make it difficult to be confident that automated rebuilds do not override the sometimes important changes that have been made. 3.3 Maintenance and Other Problems Maintenance of AustLII databases is generally handled fairly well however there are a number of occasions when manual editing is required. Manual editing is difficult to track and labour intensive. It is important to track such things as the removal of a court case that has fallen under a suppression order; updating and checking legislation; and correcting or updating documents that contained errors. Unfortunately, current methods do not allow audit trails to be developed, and make it difficult for data providers to update their own databases to check and correct errors. The current system also does not allow for particularly sophisticated user authentication and so requires updates to be 'hand checked' by staff members before being uploaded onto the live system. AustLII is currently conducting research into digital signatures and electronic delegation of legal authority. However there must first exist a technical platform from which to test such systems. AustLII faces many other technical issues, some of which have to do with scalability and some of which are concerned with the constant imperative to add functionality. Some of the other items that are on the technical agenda include:
AustLII has always sought to automate as much as possible, and this has been one reason why AustLII has been able to build such a large legal database so quickly. However the 'glue' which keeps AustLII's parts together is becoming stretched and it has become clear that it is time to start planning and designing for the next development cycle: the 'next generation' of AustLII. What AustLII has come to need is a sophisticated document management system designed specifically for the web. Such a system would include a common toolset and standard practices, while still remaining flexible and tailorable to the unique capabilities and data formats of data providers. This would not only help solve the problems of the production server but go some way to providing a platform for continuing AustLII's original R&D aims. AustLII's new Anarchivist project consists of four emerging technologies, the first three of which are based on open standards. These are:
LDAP stands for Lightweight Directory Access Protocol. This is an open standard derived from X.500 - only without all the intervening OSI layers. LDAP is a hierarchical, distributeable directory service (ie a database). One advantage of LDAP over traditional relational databases is that it naturally allows us to organise AustLII's information collections in a hierarchical and potentially distributed manner. Hierarchies are how users are used to accessing complex databases, and how AustLII's maintainers are used to organizing them. While most developers view LDAP as a way of maintaining distributed phone and e-mail directories for personnel, LDAP's chief advantage lies in the flexibility of the objects it can store. A database maintainer can create a schematic for any kind of hierarchical database they care to create, and then populate the database and enforce the schema to ensure data integrity and consistency. For AustLII, LDAP can therefore become the backbone of an extensible and distributed document management system. What such a system would provide is a central repository of meta-data[ 25 ] on every document in the AustLII database, easily organised into a logical hierarchy. The potential of such a system, from AustLII's technical point of view, is enormous. Many of AustLII's 'blue sky' technical plans rest on such a system being in place. However it is important to emphasise that the end goal is to find ways to increase access to justice through better access to legal information and to avoid building structures and technologies that do not contribute to that goal. Tim Berners-Lee's original vision of the World Wide Web differed significantly from what we have today in one important respect: the current web methodology involves publishers, who maintain control over content, and users, who are generally passive consumers of information. The original vision was that the web would be a collaborative medium - a global conversation. However, at the time that Netscape and the web gained mainstream media attention, only half the picture had been implemented. To describe most web sites as 'interactive' is to completely misunderstand the term - the true potential in that word has barely been realised. WebDAV is a set of extensions to the HTTP standard that allows web clients to update server documents in a secure manner. A WebDAV server consists of 'collections', which are analogous to directories, and documents. WebDAV specifies a set of protocols for creating, editing, moving and deleting these documents and collections. WebDAV allows a genuinely distributed authoring environment. An organisation like AustLII can benefit from WebDAV in a number of ways. It can be used internally as the mechanism for updating databases. It could also later be used by the courts themselves, to update and maintain their own collections. AustLII's current plan for WebDAV is to be the interface protocol to Anarchivist - the document management system. Some important deviations from the current WebDAV standard may be required. For example, Anarchivist will be required to track not only documents local to AustLII, but also documents and document collections existing on remote servers. This will require WebDAV clients to be able to update the meta-data relating to a document, but not the document itself. There is also poor client support in the current environment, however strong client support is not required yet for Anarchivist to work well. XML is the eXtensible Markup Language. XML is a simpler version of the popular SGML. It is designed to lower the costs (in terms of time, money and expertise) associated with using SGML to represent structured documents. It is also designed specifically for use on the web, with expanded linking capacity beyond that currently offered by HTML. XML is already supported by a number of web browsers and is likely to replace HTML over the next five to ten years. XML is a crucial part of the WebDAV protocol, since it forms the basis upon which clients and servers communicate in a WebDAV environment. The early HTML standards focused on representing data by describing what it is (eg 'this is a heading') rather than how it should be displayed (eg 'bold, 14 pt Times Roman'). However the standard was designed around representing academic papers, and allowed authors very little control over how documents were displayed. This led to browser makers extending HTML in unplanned (and occasionally bizarre) ways. While the need to represent structural information in documents is very important, it is also clear that the variety of applications upon which HTML is built requires a more flexible approach to both the structuring and display of data. This is the realm of SGML, a 'language for writing languages' upon which HTML is built. Much work has already been done in the legal domain using SGML[ 26 ]. However SGML is a complicated language and requires significant investments of time and money before it can be put to practical use. XML is an initiative supported by the World Wide Web Consortium and has been designed as a simplified version of SGML. AustLII's immediate concern with XML is as the language used by WebDAV servers and clients to communicate. However AustLII has already begun long term planning for switching to XML as its primary data representation standard. The ability of XML to support legacy data in a structured way will help this process. AustLII's current search interface is based on Perl CGI scripts which interact with the sino process using TCP/IP sockets. On the one hand this allows sino processes to be distributed among multiple machines, allowing for some form of load balancing. However there are considerable performance overheads associated with each component of the search interface. Perl is interpreted and must re-compile the interface script for each search. The CGI protocol requires a new process to be 'forked' (started) for each incoming search. And communicating with sino over TCP/IP places extra load on the local network. AustLII's new search interface is based around two technologies:
In addition to the interface changes, the new search interface introduces the concept of a virtual concordance . A virtual concordance is one or more physical concordances, which may be associated with zero or more mask paths. Mask paths in sino are the mechanism by which search results are restricted (used for example when a user only wants to search High Court cases). By combining concordances and mask paths into one virtual concordance architecture, AustLII has been able to introduce the simple but powerful World Law search facility[ 28 ]. The change in interface architecture from Perl/CGI to sinoAPI/FastCGI has led to performance improvements well beyond initial expectations. AustLII usually processes one search a second, however at peak times the rate may increase to two searches per second. However performance testing revealed that AustLII's maximum search performance under heavy load was just under two searches per second in ideal circumstances. This created a serious bottleneck with a major impact on system performance during peak times. While sino itself was very fast, its interface to the web was not scaling. The table below gives performance figures obtained during development. The searches were conducted on an otherwise idle web server. Each test was conducted twice, with the results of the first test discarded. This removed the issue of caching and disk head seek times. The performance figures revealed a 'base case' sixteen fold increase in search capacity.
Table 1: Performance figures for sino searches The results indicate the impact of the old interface on overall performance. In the new FastCGI model, performance is much more closely tied to the performance of sino itself (hence the more pronounced drop in searches per second when a more complicated search was done). It is important to note that the performance figures are only relative - the tests were conducted on a significantly slower machine than the current production server (whose current maximum search rate is approximately 1.5 searches per second). In the new Anarchivist , document meta-data is stored in LDAP objects. Actual file data is stored in the Unix file system, using a simple mapping between LDAP distinguished names and file system paths. Some objects will be 'remote' in that there will be no corresponding local data file. To update the meta-data, a modified WebDAV protocol will allow updated information to be sent via an XML encoding. Where the file contents itself are to be created or modified, WebDAV will be used to store both meta-data and document body. In the medium term, HTML will be the data format for document storage, however Anarchivist should also allow for the original 'pristine' source to be stored along with the HTML version. The contents of the Anarchivist document repository should be 'mirrored' to the local file system, for 'static page' serving by the web server. Standard headers and footers would be added at this point, along with any output from the automated markup scripts such as findacts . This is done mainly to speed user access to the data and to provide clean source for sino to index. Anarchivist will also be able to store compressed versions of files (particularly case law), which can be served directly in compressed form to the latest browsers, or decrypted on the fly at the server end for older browsers. This saves both space on the server end and time on the client end for those clients which support streaming decompression.
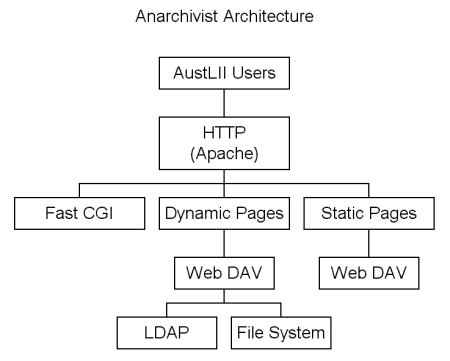
Figure 7: Simplified Anarchivist Architecture 5. Conclusion and Future Directions From a technical perspective, the AustLII project has involved the development of a number of new approaches to dealing with legal information. The current system reflects a mixture of the practicality necessary for a production service with a large user base and ongoing research based experimental systems which attempt to expand the expectations that users can reasonably expect. AustLII hopes that over the next year, the emerging Anarchivist platform will serve as the basis for new research projects, including:
All of the above must be tempered with AustLII's usual pragmatic approach to technology and focus on broad public policy goals. Footnotes 1. Greenleaf G et al, 'Introduction to the AustLII Papers', Background papers for presentations by AustLII staff at the 'Law via the Internet 97' Conference, 25-27 July 1997. 2. Andrew Mowbray, Graham Greenleaf, Geoffrey King and Peter van Dijk. 3. Source: 'Where did we go in Australia?', < http://usrwww.mpx.com.au/~ianw/> (as at 1 July 1999). 4. Austin D, 'AustLII User Survey 1998', < http://www.austlii.edu.au/austlii/survey/> (as at 30 September 1998). 5. An Enterprise 3000 with 2 x 400MHz CPUs with 1.3G of memory called 'bar' and two Sparc Ultra 170s with 256M of memory called 'bronte' and 'bondi'. 6. Mowbray 1995-. See Mowbray A 'Sino User Manual' AustLII 1996 <http://www.austlii.edu.au/austlii/ sino_full.html> and Greenleaf G, Mowbray A and King G `Public legal information via Internet: AustLII's first six months' Law Technology Journal, CTI Law Technology Centre, Vol 4 No 2 November 1995, 5-10, ISSN 0961-6902 (also in Australian Law Librarian, Vol 3, No 4-5, 1995, 144-153, ISSN 1039-6616). 7. See Greenleaf G , Mowbray A, Tyree A (1992) 'The DataLex Legal Workstation - Integrating tools for lawyers' Vol 3 No 2 Journal of Law and Information Science (1992) 219 -240 (also in Proc. Third Int. Conf. on Artificial Intelligence and Law, ACM Press, 1991). 8. King and Austin 1996-. See Greenleaf G, Mowbray A and King G (1997) `New directions in law via the internet - The AustLII Papers' Journal of Information, Law and Technology (JILT), Issue 2, 1997, University of Warwick Faculty of Law, (electronic journal) located at < http://elj.warwick.ac.uk/jilt/issue/1997_2 >, 30,000 words (also published as `The AustLII Papers' in Proceedings of the Law via the Internet `97 Conference, AustLII, UTS/UNSW Faculties of Law, June 1997). 9. ibid. 10 . wysh was originally written by Geoff King and Simon Cant in 1996. See Greenleaf G, Mowbray A, King G, Cant S and Chung P (1997) 'More than wyshful thinking: AustLII's legal inferencing via the World Wide Web', Proc. 6th International Conference on Artificial Intelligence and Law (Melbourne 1997), ACM Press, Association of Computing Machinery, New York, 1997, 9 pages. 11. Mowbray 1993. See Greenleaf G, Mowbray A and van Dijk P (1995) 'Representing and using legal knowledge in integrated decision support systems - DataLex Work Stations', Artificial Intelligence and Law, Kluwer, Vol 3, Nos 1-2, 1995, 97-124. 12. Apache Software Foundation, < http://www.apache.org/>. 13. Free Software Foundation, < http://www.fsf.org/>. 14. Wall, L and the Perl Software Consortium, < http://www.perl.com/>. 15. Vendor and medium neutral citation provide a system of court assigned unique descriptors for cases based upon a court designator, a year, a decision number and, if necessary a paragraph number. 16. Sino currently consists of less than 8,000 lines of C code. 17. And hence the name Sino - ' Size is no Object '. Apart from being a reaction to the very slow retrieval times of glimpse vs the very good concordance ratios that it was achieving, the name was also meant to reflect the fact that sino could handle very large text databases. 18. 3,969 as at 19 July 1999. 19. Lawrence & Giles, 'Accessibility of information on the web', Nature (Vol 400), 8 July 1999. 20. Austin, 'AustLII 1998 Survey Results', < http://www.austlii.edu.au/austlii/survey/> (as at 30 September 1998). 21. More accurately, 2 31 or 2,147,483,648 bytes. 22. See The Sino Search Engine , above for an explanation of a 'concordance file.' 23. See < http://scaleplus.law.gov.au/>. 24. See < http://www.thelaw.tas.gov.au/>. 25. For AustLII's purposes, such things as document title, data source, publication date and version history. 26. Poulin, Lavoie & Huard, 'Supreme Court of Canada's cases on the Internet via SGML', Law via the Internet 1997 Conference Proceedings, 25-27 July 1997. 27. See < http://www.fastcgi.com/> 28. See < http://beta.austlii.edu.au/links/World/>
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||